Software Delivery Projects and Feedback
Please Note: This is a draft page and is still being worked on.
Complexity science has identified that feedback is one of the critical ingredients required of a system to generate complex behaviour. The science also suggests that we should not rely upon intuition when considering how to set-up, initialise and regulate feedback loops because the predictability of their behaviour will vary, unpredictably. We also have to be aware that a great deal of the general analysis on feedback loops that has contributed to complexity science is based upon systems that can be modelled in a highly mathematical manner and in which the influence of the feedback can also be represented mathematically. Unfortunately projects, and more generally human based systems, cannot be represented by partial differential equations so we have to be careful when applying generic ideas from complexity science.
Given the gap between what complexity science may tell us about feedback and the specific nature of feedback in projects it seems that we need to delve more deeply into the nature of feedback within a project context if we want to use the science to help us moderate the behaviour of our projects.
What is a Feedback?
In its most basic form feedback occurs when two systems are connected in such a way that they influence each other and their dynamics become strongly coupled. They are often termed ‘feedback loops’ because the connection implies that some part of the behaviour from one or both systems is input into the other system (technically this is termed a, ‘closed loop feedback’, but there are also open loop feedback configurations).

The Project as a Network of Feedback
A project is a system and project members are an active and influential component of it. The system’s state, which itself is a vast complex mixture of characteristics is changing continually because every minute something is changing. The project’s state is the result of a complex chain of dynamic influences that are generated by, and themselves influenced by, all of the components including, the people, the infrastructure, evolving and propagating information streams and the evolving product itself. All of these components have feedback relationships with other components. As we look deeper into a project’s structure we uncover feedback at all levels of scale and a project starts to become a complex nest of feedback. In fact from this viewpoint a project has a level of self-similarity. As the project progresses new feedback paths are activated whilst others decay and cease and the larger the project the more complex this dynamic network feedback becomes.
My own view is that feedback is probably the characteristic that most influences the complex behaviour of a project and therefore it is worth understanding in some detail. For the remainder of this article I am going to concentrate on closed feedback that we often term, ‘feedback loops’ as this is the more complex feedback to address in a project environment
The Structure of Feedback Loops
For the purposes of analysis we can define two categories of feedback loops, which will now be described.
Process Loops
Process loops are an integral structure to any project and are required to develop and deliver the product. The process loop is found in activities that are critical to that delivery, such as:
-
Gathering and prioritising requirements
-
Implementing features/functions with user feedback
-
Testing the features and functions
-
Integrating and building a delivery
-
Delivering the software into the customer’s environment.
Process loops are focused on directly supporting or developing the product, therefore monitoring, management or planning tasks are not process loops. Some may say that a level of management and monitoring is a necessity and this may be so, but to analyse the behaviour of the project as a system one could argue that they are in fact superfluous.
Process loops develop as a natural part of the development process and examples include user feedback or testing-re-work loops. The process loops tend to come and go as different activities associated with product development and delivery become active. Process loops exist at every scale within a project from an individual’s creative process to large scale software integration, build and test. In fact if one considers a larger scale loop such as development and testing then it can be viewed as a network of smaller scale feedback loops that are coupled in various ways. A simple model of a process feedback loop is shown below.

In this case there is a process A from which a project deliverable A is evolving. At given times deliverable A is sampled by process B to generate deliverable B, part or all of which is then fed back into process A and effects the future evolution of deliverable A.
Each process has internally generated influences and also external influences from the outside world so the process is influencing itself and also influencing the outside world. These influences may also be feedback loops.
Each of these processes will have other inputs but they are ignored in this representation. Process feedback loops occur at all scales of the project and in fact the dynamics of an individual developer who may be coding a feature from a description, specification or with a user is a prime example of a small scale process feedback loop.
Whether these loops are formalised and procedural or more ad-hoc, from a system’s perspective they are contributing in some manner to the overall behaviour of the project.
The process loop just goes through the motions. There is no intelligent moderation of its behaviour at any point in the loop. To effect such moderation we have to introduce the second category of feedback loop.
Control Loops.
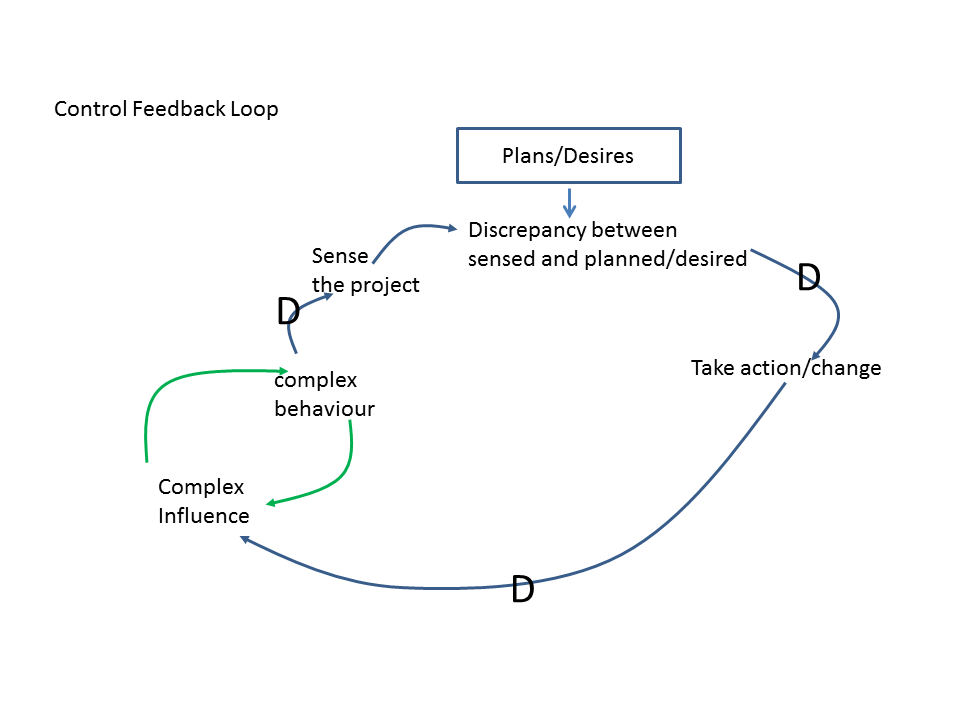
These loops are constructed to sense what is going on, possibly within a process loop and take an action if required to attempt to change behaviour to within perceived or planned tolerances. In some cases it may be to increase some characteristic or in others to decrease it. Using a basic cause-effect diagram a general control feedback loop within a project is shown below.

In general we sense an aspect of the project in some manner and then compare our measurements or perceptions against our expectations and then from this we decide whether to take action to influence the system.
-
As members of the project team we in some way ‘sense the project’s behaviour, hopefully through some objective observations or measurements of specific characteristics. This means that we only ever get a very limited perception of the entire behaviour of the project. Let’s consider the sequence of events in a typical control loop.
-
We then take time (identified as a ‘D’ on the diagram) to make sense of our observations and in some manner compare it to our expectations. In general our expectations are far too restricted and optimistic and usually reflect our desires or lack of knowledge through information hiding rather than any analytic appreciation of what the project’s behavioural envelope may be.
-
We then take more time to decide what to do and again we fall foul of our limited ability to make good judgements and decisions.
-
We then may take an action that, in general, is not based upon an understanding of the dynamics of the project.
-
This action takes time to implement and for its influence to propagate through the project; a fact that we seldom take into account.
During the period between sensing the project and the implemented change propagating through the project the system’s state has changed and this means that the applied change based upon a previous state is even less effective and the outcome even less predictable. It seems reasonable to suggest that the larger the project the more control loops exist and hence the greater the number and complexity of the influence on the overall project’s behaviour and hence the less effective and predictable a larger proportion of our changes would be. Also as we enter the project’s complexity storm the number of generated feedback loops increases in a highly non-linear fashion and hence things are even worse during this period.
With all of this nested and highly complex change occurring it would seem that our projects are being continually perturbed in ways that may have good intention but are untimely, unpredictable and to some degree are ineffective. This analysis would seem to suggest that every control loop is in fact a risk and that this risk increases with:
-
The scale of the process to which the loop is being applied
-
The speed at which we implement any change
-
The understanding we have of the parameters against which we are comparing our perceived state of the system.
I believe that control loops can give us a false sense of security and it is the unnecessary and poorly implemented control loops that leads to a great deal of the instability in project behaviour. In fact I wonder if we end up implementing changes that require lower level control loops by individuals and teams to moderate the effects of the initial change.
The idea of control and control loops comes from the more mathematical treatment of feedback and I believe that in our case these should not be termed, ‘control loops’ but instead, ‘regulation loops’. The idea of control suggests that we know exactly what we want and how to achieve it and this is far from the case. Instead what we need to do is have less, but more informed feedback that attempts to regulate or moderate the behaviour within a envelope of acceptable behaviour.

General Principles
I think that from this initial analysis we can extract the following principles:
-
Apply control loops at the lowest scale possible. The best being at individual level as part of enabling localised adaptation. In fact localised adaptation is affected as part of a control loop.
-
Don’t stick your nose in if it’s not required because this usually means applying a higher level control loop.
-
We need far better understanding of the project through understanding and modelling its dynamics so that we have more realistic boundaries against which we can compare current behaviour. The worst thing to do is to just pick a boundary like cost or time out of the air because it will cause us to make changes to the project that are against its natural dynamic behaviour and that are likely to result in greater complexity, more uncertainty and an increase in time scales.
In the next section I want to dig deeper and understand how we can combine control loops with process loops in a practical example and start to understand its dynamic behaviour.
Bringing it all Together
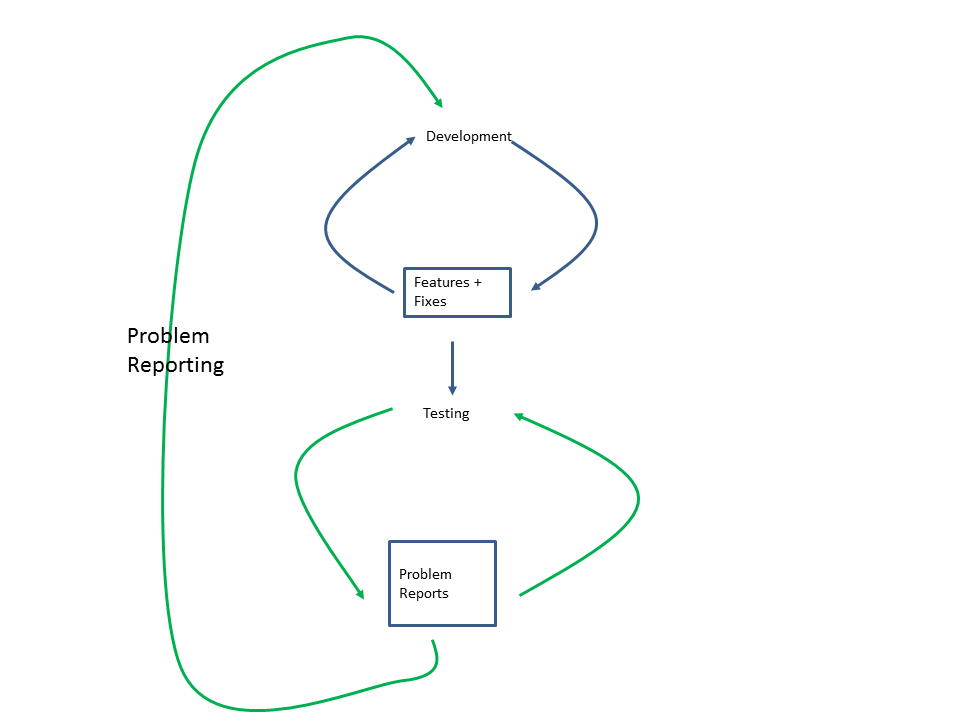
Let’s look at the common and seemingly simple example of the development and test process loop in which software is developed then passed to a testing process that detects problems which are fed back to development and the updated software is returned to the testing process. This simple process loop can be seen below.

We can surmise that the state of the system is an interplay between the dynamics of the development and test processes. We cannot intuitively understand the dynamics of this process loop, however we can get a feel for its boundaries of behaviour by considering the influences when the two processes are at the extremes of their behaviour. It would seem reasonable to consider that the effectiveness and efficiency of each process to be primary characteristics that influence the overall behaviour of each process loop.
-
Effectiveness is a measure of the process’s likelihood of seeding defects, combined with its coverage of the required features or testing.
-
Efficiency is the rate at which the process can process the input deliverables.
We can sense the effect of the dynamics through the variability with time of the following:
-
The backlog of new code waiting to be tested
-
The backlog of fixes waiting to be retested
-
The backlog of problem reports awaiting to be processed by development
-
The backlog of new features waiting to be developed by development.
Now let us try to understand something of the dynamic behaviour if the development and testing processes are at the extremes of their behaviour.
If we assume development is highly efficient and effective and test isn’t then we are going to end up with a backlog in test and development could be sitting around twiddling their thumbs waiting for the problem report backlog to increase. However because test has limited effectiveness and efficiency then the few problems are likely to come through to development quite slowly. One might be tempted to move development on to other things, however the fact that resources will be needed to investigate and fix the slow stream of problems generated by testing means that we are perturbing future development processes and creating uncertainty within it. Also by nature of context switching we may be affecting the effectiveness of the fixes by development.
If we now assume that development aren’t that effective or efficient but testing is then we are going to increase the backlog of problems for development to address and in this case testing may be sitting around. This increase in the backlog of problems will also perturb the development process’s ability to develop the new features. Once again we could introduce uncertainty into future test related processes if we re-assign test resources.
Another key question is what behaviour would result in an optimum time for completion of this activity. Is there an optimal dynamics (near to equilibrium) whereby both processes work at an effective rate to achieve the end result in a optimised duration and within reasonable behavioural tolerances.
I have not here complicated the situation by discussing prioritisation schemes, fix strategies for the problem backlog or software delivery approaches into testing. However all of these will have an effect on the dynamics of the loop.
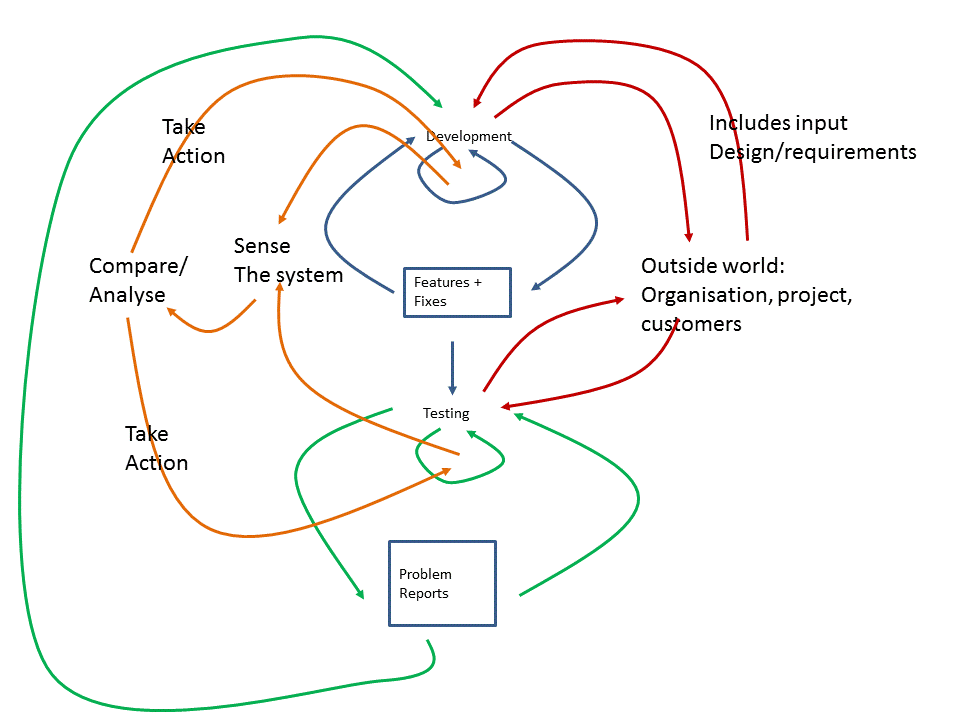
In reality each of the processes is internally influenced by internal perturbations due to infrastructure glitches and resources not being available and many other issues. The processes are also being perturbed by external influences from the wider project systems and the organisation and customers. So a more realistic model would be as follows:

Another big question is how would the dynamics of this loop be affected by the size of the feedback task in terms of the amount of software or features to be delivered and the complexity of the software and its associated data. Experience and a qualitative analysis would suggest that small scale deliverables which are functionally simple being delivered into small team environments will have low complexity dynamics and be reasonably predictable, of short duration and with few major swings in behaviour. However for large projects this seemingly simple development and test loop, often just represented as two bars on a Gantt chart, can exhibit complex dynamics and requires a level of understanding to moderate or tune its behaviour. To moderate such large scale process loops we introduce a bit more structure and some control loops so our model may look something like this:

To try to answer some of the questions that I have posed I am going to attempt to create a model of this activity and run simulations using Wolfram Mathematica to answer the following questions:
Still working on this. More to follow …